Scrapy and Elasticsearch
Search Meetup Karlsruhe, 19.07.2014
Why Scraping
- not your data
- data is not easily accessible
- data is already aggregated
Scraping examples
- Price comparison website
- News portal
- Financial information
- Aggregation sites
- Intranet search
- Testing/Monitoring
Example
Only an example!
Meetup.com has an API, use it
Build it yourself?
- Limit requests
- robots.txt
- Extensible process
Why Scrapy
- Python
- Asynchronous, Non-Blocking
- Item Pipeline
- Lots of features
Architecture
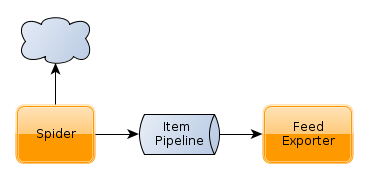
Installation
pip install ScrapyScaffolding
~/temp$ scrapy startproject meetup
~/temp$ find meetup/
meetup/
meetup/scrapy.cfg
meetup/meetup
meetup/meetup/settings.py
meetup/meetup/__init__.py
meetup/meetup/items.py
meetup/meetup/pipelines.py
meetup/meetup/spiders
meetup/meetup/spiders/__init__.pyItem
from scrapy.item import Item, Field
class MeetupItem(Item):
title = Field()
link = Field()
description = Field()
Spider
from scrapy.spider import BaseSpider
from scrapy.selector import Selector
from meetup.items import MeetupItem
class MeetupSpider(BaseSpider):
name = "meetup"
allowed_domains = ["meetup.com"]
start_urls = [
"http://www.meetup.com/Search-Meetup-Karlsruhe/"
]
def parse(self, response):
responseSelector = Selector(response)
for sel in responseSelector.css('li.past.line.event-item'):
item = MeetupItem()
item['title'] = sel.css('a.event-title::text').extract()
item['link'] = sel.xpath('a/@href').extract()
yield itemCrawling
scrapy crawl meetup -o talks.json
2014-07-24 18:27:59+0200 [scrapy] INFO: Scrapy 0.20.0 started (bot: meetup)
[...]
2014-07-24 18:28:00+0200 [meetup] DEBUG: Crawled (200) Crawling
less talks.json
{"link": ["http://www.meetup.com/Search-Meetup-Karlsruhe/events/178746832/"],
"title": ["Neues in Elasticsearch 1.1 und Logstash in der Praxis"]}
{"link": ["http://www.meetup.com/Search-Meetup-Karlsruhe/events/161417512/"],
"title": ["Erstes Treffen mit Kurzvortr\u00e4gen"]}
Crawling Details
Crawling Details
Crawling Details
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import Selector
from meetup.items import MeetupItem
class MeetupDetailSpider(CrawlSpider):
name = "meetupDetail"
allowed_domains = ["meetup.com"]
start_urls = ["http://www.meetup.com/Search-Meetup-Karlsruhe/"]
rules = [Rule(SgmlLinkExtractor(
restrict_xpaths=('//div[@id="recentMeetups"]//a[@class="event-title"]')),
callback='parse_meetup')]
def parse_meetup(self, response):
sel = Selector(response)
item = MeetupItem()
item['title'] = sel.xpath('//h1[@itemprop="name"]/text()').extract()
item['link'] = response.url
item['description'] = sel.xpath(
'//div[@id="past-event-description-wrap"]//text()').extract()
yield item
Playing nice!
- RobotsTxtMiddleware
- AutoThrottle
Playing nice is optional!
- User agent rotation
- Proxy rotation
Elasticsearch
- Index Item in Elasticsearch
- Module using pyes
Architecture
Architecture
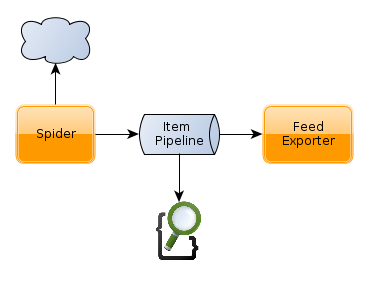
Installation
pip install "ScrapyElasticSearch"settings.py
ITEM_PIPELINES = [
'scrapyelasticsearch.ElasticSearchPipeline',
]
ELASTICSEARCH_SERVER = 'localhost'
ELASTICSEARCH_PORT = 9200
ELASTICSEARCH_INDEX = 'meetups'
ELASTICSEARCH_TYPE = 'meetup'
ELASTICSEARCH_UNIQ_KEY = 'link'
Gotchas
- Map type in advance
- No bulk index